Mastering Developing Scalable AI Solutions for Success
Learn essential strategies for developing scalable AI solutions. From prototypes to production, optimize your AI architecture and MLOps workflows.
Building a scalable AI solution isn't just about writing clever code. It's about engineering a system that can gracefully handle more data, more users, and new business demands without falling over or burning through cash. The secret is adopting a production-first mindset right from the start. Scalability can't be a feature you tack on later; it has to be baked into the design from day one.
This really comes down to a smart mix of flexible architecture, tough-as-nails data pipelines, and some seriously disciplined operational habits.
Why Do So Many AI Projects Stall Out?
We’ve all seen it happen. A genius AI prototype works flawlessly in the lab but completely implodes when it meets the real world. That journey from a promising proof-of-concept to a solid, enterprise-ready system is a minefield, and it's where an astonishing number of projects get stuck.
It's a frustratingly common story. Research suggests a huge chunk of AI initiatives never actually graduate from the experimental phase. The models themselves might be spot-on, but the underlying system just wasn't built for the big leagues.
This isn't just a tech problem—it's a strategic blunder that comes from kicking the scalability can down the road. When your solution can't grow with the business, you're in for a world of hurt.
The Real Price of a System That Can't Scale
Putting scalability on the back burner creates some serious business risks that can tank your entire AI investment. A successful prototype can give you a false sense of confidence, hiding major architectural flaws that only show up when the pressure is on.
The fallout usually hits in a few key areas:
- Performance Dives: As more people use the system or you pump more data through it, everything slows to a crawl. Latency goes through the roof, response times get awful, and users lose faith fast.
- Costs Skyrocket: A system that wasn't designed to grow efficiently forces you into expensive, panicked fixes. The default move is often just throwing more powerful (and pricier) hardware at it, which is a recipe for unsustainable operational costs.
- You Can't Adapt: Business never stands still. A rigid AI solution can't easily integrate new data, roll out new features, or pivot with market changes. Before you know it, it’s a digital relic.
The biggest hurdle is moving from a pure data science mindset—where model accuracy is king—to a production engineering mindset, which obsesses over reliability, maintenance, and efficiency when things get real.
This guide lays out a battle-tested framework for getting this right. By following a structured process grounded in our AI co creation philosophy, you can build systems that are truly designed to grow. We're going to treat scalability not as the finish line, but as the foundation for everything you build.
Building Your Architectural Blueprint for Growth
Before you write a single line of code, you need a solid blueprint. This is where the real work of building a scalable AI solution begins—not in the code, but in the strategic decisions that will define your project's future. It's about looking past today's problems to design for tomorrow's demand and aligning your AI goals with what the business actually needs to achieve.
This strategic groundwork is everything. I’ve seen it time and time again: companies dive into AI, but their initial architectural choices simply weren't built for growth. The numbers back this up. While around 78% of organizations are using AI, a staggering 1% feel they've actually reached AI maturity. That massive gap is often a direct result of a shaky foundation.
Choosing the Right Architectural Pattern
Your architectural pattern is the most critical choice you'll make. It dictates how your system will handle growth and is the difference between a system that scales gracefully and one that requires a complete, costly overhaul down the road.
This is all about trade-offs. Sure, a monolithic architecture might get you to a prototype faster, but it quickly becomes a bottleneck as your application gets more complex. On the other hand, a microservices architecture breaks the system down into smaller, independent services. Think of it as a collection of specialized tools instead of one giant multi-tool.
This modular approach is the key to scaling efficiently and building a resilient system.
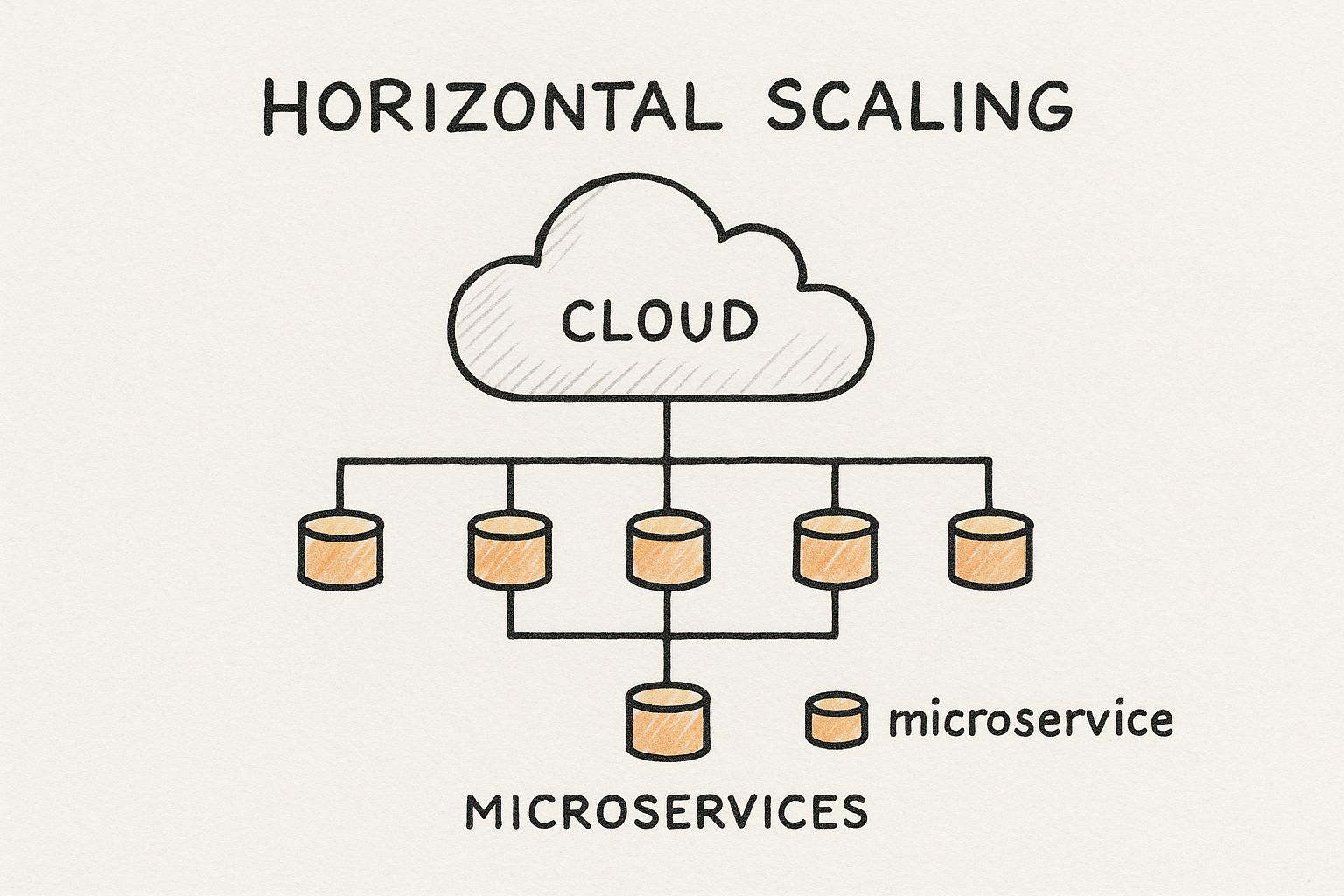
When you look at it this way, it's easy to see the benefit: each service can be scaled independently. If your data-processing component is under heavy load, you can give it more resources without touching anything else.
To help you decide, let's look at the most common architectural choices side-by-side.
Comparing Architectural Choices for AI Scalability
Picking the right pattern isn't just a technical decision; it's a business one that impacts your budget, team structure, and ability to adapt. This table breaks down the practical trade-offs to help you map your project's needs to the right foundation.
| Architectural Pattern | Best For | Scalability | Cost Model | Management Complexity |
|---|---|---|---|---|
| Microservices | Complex applications with diverse functionalities. | High; scale individual components. | Pay-per-service; can be complex. | High |
| Serverless | Event-driven tasks and unpredictable workloads. | Excellent; scales automatically to zero. | Pay-per-execution; cost-effective. | Low |
| Monolithic | Simple applications and rapid prototyping. | Low; must scale the entire application. | predictable but inefficient at scale. | Low to Moderate |
Ultimately, your choice here should be guided by a clear, long-term vision. This is where a well-defined AI strategy becomes invaluable, as it translates business goals into the technical requirements needed to make these foundational decisions. You can see what this looks like in a Custom AI Strategy report.
Selecting a Future-Proof Tech Stack
Once you've settled on an architecture, it's time to pick your tools. The goal here is to select a technology stack that not only supports your chosen pattern but also keeps you from getting boxed in by a single vendor.
Vendor lock-in is a real threat. It can stifle innovation and quietly inflate your costs over time. A smart way to avoid this is to take a cloud-agnostic approach using open-source tools. Kubernetes is the perfect example. It lets you orchestrate containers across different cloud providers—whether it's AWS, Azure, or GCP—giving you the freedom to move workloads or mix and match the best services from each.
When building out your stack, you should also think about:
- Data Processing: For handling massive datasets in parallel, look at tools like Apache Spark or Apache Flink.
- Model Serving: To deploy models into production with low latency, you'll want frameworks like TensorFlow Serving or TorchServe.
- Infrastructure as Code (IaC): Using tools like Terraform or Ansible is non-negotiable. It makes your infrastructure reproducible and far easier to manage as you scale.
Getting this blueprint right from the start is what separates the projects that succeed from those that stumble. By building a technical foundation that truly supports your long-term vision, you create a system that’s ready to evolve right alongside your business.
Designing Data Pipelines That Won't Break Under Pressure
An AI system is only as good as the data it’s fed. When you're building for scale, that data flow becomes a high-pressure pipeline. I've seen too many promising AI projects die a slow death because their data infrastructure was brittle and couldn't handle the load. It's like putting a high-performance engine in a car stuck on a congested highway—as soon as data volume picks up, everything grinds to a halt.
Building a resilient data pipeline means you have to plan for the messy reality of the real world from day one. It's about creating a system that can gracefully handle ever-increasing volumes and varieties of data without collapsing. This isn't just about getting data from point A to point B; it’s about managing the entire data lifecycle, from the moment it’s collected to the instant it fuels a model's prediction.
From Raw Data to Actionable Insights
The journey from raw, chaotic data to clean, structured features is where most scaling challenges really surface. You need a rock-solid process for ingestion, processing, storage, and governance that operates like a well-oiled machine, no matter how much you throw at it.
Think of it as building a sophisticated factory assembly line. Each station has to be efficient, reliable, and capable of handling surges in production without causing a massive pile-up downstream.
- Data Ingestion: This is your factory’s receiving dock. It needs to handle data from all kinds of sources—APIs, databases, streaming feeds—without dropping any packages. For this to scale, you need tools that can manage high-throughput, asynchronous data streams.
- Data Processing: Here’s where raw materials get cleaned, transformed, and refined. This involves the crucial work of filtering out noise, normalizing formats, and performing feature engineering—the real art of creating predictive signals your model can actually use.
- Data Storage: Finally, the finished goods are stored. Your choice of storage is absolutely critical for both performance and cost-effectiveness, especially as your data footprint inevitably grows.
A classic mistake is optimizing for a perfect, static dataset during development. The truth is, production data is a constantly moving target. Your pipeline has to be built to expect and handle this chaos gracefully, not as some rare exception.
To make sure the information feeding your AI models is solid, looking into effective data governance practices is a must for building robust data pipelines.
Choosing the Right Data Storage for Scale
Your storage solution directly impacts how quickly your models can be trained and how responsive your AI application feels to the end-user. Two main architectures dominate the scene—data lakes and data warehouses—and picking the right one (or often, a hybrid of the two) is a pivotal decision.
A data warehouse is like a meticulously organized library. It stores structured, processed data in a predefined schema, which makes it perfect for business intelligence and analytics where query speed and consistency are everything.
On the other hand, a data lake is more like a vast reservoir. It can hold enormous amounts of raw data in its native format, whether it's structured, semi-structured, or completely unstructured. This flexibility is a godsend for machine learning, where data scientists need the freedom to explore and experiment with raw information before deciding how to shape it.
Automating these data flows is a game-changer. It frees up your team to focus on higher-value work instead of just plumbing. This is where services like AI Automation as a Service become incredibly powerful, managing the complex workflows needed to keep your data clean, versioned, and ready for your models.
The Critical Role of Data Versioning and Governance
As your AI system evolves, so will your data and the features you engineer from it. Without a system to track these changes, you can quickly lose the ability to reproduce experiments or figure out why a model’s performance suddenly dropped. This is exactly what data versioning is for.
Think of data versioning as Git, but for your datasets. It lets you snapshot your data at different points in time, so you always know exactly which data was used to train a specific model version.
This practice is non-negotiable for maintaining accuracy, ensuring compliance, and building genuine trust in your AI system. It provides a clear audit trail that is essential in regulated industries and serves as a cornerstone of responsible AI development.
Implementing an MLOps Framework for Continuous Delivery
Think of MLOps as the engine that reliably gets your AI model out of the lab and into the real world, over and over again. This is about more than just slick automation; it’s about instilling a disciplined, operational culture around your AI systems. When you build a solid MLOps framework, you eliminate clumsy manual hand-offs, dramatically reduce deployment errors, and ultimately ship your AI solutions much faster.
This discipline is more important than ever. The AI market is growing at a staggering rate, with predictions of a 35.9% compound annual growth rate between 2025 and 2030. By the end of the decade, AI technologies are expected to contribute as much as $15 trillion to the global economy. This kind of explosive growth means that only the most robust, scalable deployment practices will keep up.
A well-designed MLOps pipeline makes every step of the model lifecycle—from data prep to deployment—reproducible, traceable, and automated. This philosophy is the foundation of our internal AI Product Development Workflow, where we focus on building systems that are ready for production right from the start.
Core Pillars of a Scalable MLOps Framework
A successful MLOps setup is built on a few essential pillars. These pieces work in concert to create a smooth, automated journey from model development to deployment and monitoring, forming the backbone for any serious attempt at developing scalable AI solutions.
- CI/CD for Machine Learning: This takes the familiar principles of Continuous Integration and Continuous Delivery from software engineering and applies them to AI. It means automating the testing and validation of not just your code, but your data and models, too.
- Robust Model Versioning: You use Git to version your code, right? The same logic applies here. You need a system to version your models, the datasets they were trained on, and even the specific configurations used. This is absolutely critical for reproducibility and debugging.
- Automated Training Workflows: Kicking off model retraining manually is slow and ripe for human error. A proper MLOps framework automates this entire pipeline, letting you retrain models on new data with a single command or on a recurring schedule.
The real goal of MLOps is to make deploying and updating models a boring, predictable, and routine event. If every deployment feels like a high-stakes drama, your process is broken.
For a great look at how to build this intelligence directly into your delivery pipeline, check out these strategies for leveraging AI in DevOps for faster software builds.
Choosing Your Deployment Strategy
Once your model is trained, tested, and packaged up, you need a safe way to release it to your users. Simply flipping a switch and swapping the old model for the new one is asking for trouble. A mature MLOps process relies on controlled deployment strategies to minimize risk.
It's like gradually introducing a new species into an ecosystem instead of just dropping it in from a helicopter. This careful approach gives you time to observe how the model performs in the real world and gives you an easy way to roll it back if things go south.
The right strategy for you will depend entirely on your specific use case, how much risk you're willing to take, and what your tech stack can support.
| Deployment Strategy | How It Works | Best For |
|---|---|---|
| Canary Release | The new model version is rolled out to a small, controlled subset of users (the "canaries") first. | Validating performance with real traffic before a full-scale release. |
| A/B Testing | Two or more model versions are run in parallel, with traffic split between them to compare performance. | Directly comparing a new model against the old one using live user data. |
| Shadow Deployment | The new model runs alongside the old one, processing real traffic without sending its predictions back. | Testing a new model's performance under production load without impacting users. |
By baking these MLOps principles into your process from day one, you build a system that is not only powerful but also resilient and adaptable. This framework transforms the complex job of managing AI in production into a streamlined, repeatable process, ensuring your solutions stay effective and valuable long after they first launch.
Keeping Your AI Solution Healthy in Production
Getting your AI solution deployed isn't the finish line—it's the starting block. The real challenge, and where a truly scalable AI solution proves its worth, is in what comes next. This is where the continuous work of monitoring, maintenance, and optimization begins, ensuring your system stays effective in an ever-changing environment.
Once your model is live, it’s facing the unpredictable nature of the real world. You can't just set it and forget it, assuming it will perform as well as it did in your controlled lab environment. You need a solid plan to track its health in real-time, focusing on the metrics that actually impact your business.
This goes way beyond just checking for server uptime. You need to be watching the key performance indicators (KPIs) that tell you how the model itself is behaving.
- Accuracy and Precision: Is the model still getting it right? How often are its predictions correct versus incorrect?
- Latency: How fast is it responding? A slow model can completely ruin the user experience, especially in real-time applications.
- Throughput: How many requests can the system handle at once? This is your direct measure of its ability to scale when things get busy.
The Silent Killers: Model and Data Drift
One of the sneakiest challenges you'll face is the inevitable creep of model drift and data drift. These are subtle but incredibly damaging issues that can quietly tank your model's performance over time, leading to bad decisions and, ultimately, lost revenue.
Data drift occurs when the input data your model sees starts to look different from the data it was trained on. Imagine a retail prediction model suddenly dealing with new buying habits after an economic shift. Model drift, also called concept drift, is when the underlying relationship between inputs and outputs changes entirely.
The real world isn’t static. If your AI system is, it’s already on its way to becoming obsolete. Catching and correcting drift isn’t just a "best practice"—it's an absolute necessity for any AI solution built to last.
If you aren't proactively monitoring for this, you won't spot the degradation until it's already done serious harm. The trick is to set up automated alerts and real-time dashboards that give your team an immediate heads-up. This way, you can catch drift before it becomes a full-blown crisis.
Strategies for Seamless Retraining and Redeployment
When you spot significant drift, you have to act. That means retraining your model with fresh, relevant data. But here's the catch: you can't just take the whole system offline for an update. A key part of our AI Automation as a Service is building strategies for seamless model retraining and redeployment that cause zero service interruptions.
Here’s how we approach it:
- Automated Retraining Pipelines: We build workflows that automatically kick off a retraining job whenever performance metrics dip below a pre-set threshold.
- Champion-Challenger Testing: The new model (the "challenger") is deployed to run alongside the current one (the "champion"). This lets you compare their performance on live data without any risk.
- Gradual Rollouts: Once you're confident in the challenger, you use a canary release or a similar technique to slowly shift traffic to it. This minimizes the risk of a widespread problem if something goes wrong.
The economic impact of getting this right is massive. In data-heavy sectors, getting AI to this scale could add an estimated $4.7 trillion in value to the IT and telecom industries by 2035. These sectors are weaving AI into critical infrastructure for everything from network optimization to predictive maintenance, which shows that scalability is all about deep, resilient integration. You can dive deeper into these industry-wide shifts and their financial implications in recent AI adoption trend reports.
By putting a rigorous monitoring and maintenance framework in place, you transform your AI solution from a one-off project into a living, evolving system. This proactive mindset ensures your model not only survives but thrives in production, continuing to deliver value as your business grows. This kind of operational excellence is a complex puzzle, and working with our expert team can bring the seasoned experience needed to build and maintain AI that truly makes an impact.
Your Path to Future-Proof AI
Building an AI solution that can actually grow with your business is a serious undertaking. It’s one part strategic planning, one part hardcore engineering, and a healthy dose of operational rigor. We’ve covered a lot of ground, from laying the architectural foundation and wrangling data pipelines to keeping your models alive and well in the real world with a solid MLOps framework.
If you take only one thing away from this guide, let it be this: scalability can't be an afterthought. It’s not something you bolt on later. You have to bake it into your process from the very first brainstorming session. When you make scalability part of your team's DNA, you stop building one-off projects and start creating AI systems that solve today’s problems and are ready for whatever comes next.
Beyond the Blueprint
Thinking about scale from the get-go is how you future-proof your investment. As we explored in our AI adoption guide, the real win with AI isn't the flashy launch—it's the system's ability to adapt and expand as your business evolves. This demands a relentless focus on a production-first mindset.
To make this real, anchor your work in these core ideas:
- Modular Design: Think in terms of independent, swappable components. This lets you scale or update one piece without tearing the whole thing down.
- Automated Operations: Get humans out of the loop wherever you can. Your deployment and maintenance cycles should run on their own.
- Proactive Monitoring: Don't just watch for crashes. You need to be actively hunting for signs of performance decay and model drift before they become a problem.
The road to scalable AI isn't a sprint; it's a marathon of constant refinement. Your goal is to create a living system that learns, adapts, and keeps delivering value—transforming AI from a cool project into a core business function.
As you move forward, don't forget that this is genuinely complex work. Teaming up with our expert team can bring the seasoned experience needed to handle the tricky details of building AI solutions that last. They have the know-how to help you turn a big vision into a resilient, scalable reality.
Got Questions? We've Got Answers
Here are some of the most common questions we get from teams diving into scalable AI, answered with a dose of real-world experience.
What’s the Single Biggest Mistake Teams Make When Scaling AI?
Hands down, the most common pitfall is thinking the job is almost done once the model works. I've seen teams get a model running in a Jupyter notebook and assume they're 80% of the way there. In reality, they've barely hit the 10% mark.
Getting a model to work is just the beginning. The real heavy lifting comes from building the production-ready systems around it. We're talking about hardened data pipelines, solid MLOps automation, comprehensive monitoring, and feedback loops that actually work. It’s less about data science at that point and all about disciplined software engineering. An effective AI requirements analysis early on can prevent this misconception by scoping the full engineering effort.
How Do I Pick the Right Cloud Platform for a Big AI Project?
Honestly, the "best" choice between AWS, Google Cloud, and Azure usually boils down to what your team already knows, your budget, and whether you need a specific tool, like Google's TPUs or AWS's SageMaker ecosystem.
But here’s my pro-tip: don't marry your cloud provider. A cloud-agnostic strategy is almost always the smartest long-term play. By using an orchestration tool like Kubernetes, you build a system that isn't locked into one vendor. This gives you the freedom to cherry-pick the best services from any provider and adapt as your needs (and their pricing) change.
What Exactly Is Model Drift and Why Should I Care?
Think of model drift as the natural aging process for your AI. A model trained on last year's data will inevitably get worse over time because the world changes. Customer behavior shifts, market conditions evolve, and the data your model sees in production starts to look different from what it was trained on.
This is a massive deal for scalability. An unmonitored model doesn't just fail; it fails silently. It starts making bad predictions, which can quietly sabotage business decisions and erode value. A truly scalable system needs to have automated checks in place to spot this decay early, flag it, and kick off a retraining process to keep the model sharp and reliable.
How Can I Realistically Estimate the Cost of Building a Scalable AI System?
This is the million-dollar question, and the answer is... it depends. The price tag can swing wildly based on the complexity of what you're building.
Your main cost drivers will almost always fall into these three buckets:
- Cloud Infrastructure: This is a big one. You're paying for the compute power and data storage, and those bills are recurring.
- Specialized Talent: Good MLOps and data engineers are not cheap. They're in high demand for a reason.
- Software & Tools: Licenses for proprietary platforms or specialized software can quickly add up.
While the upfront investment can feel steep, remember that a well-designed system saves a ton of money in the long run by automating tasks and boosting efficiency. To get a handle on your specific needs, our AI strategy consulting tool can help map out resources against your goals. It also helps to look at real-world use cases to see how other projects were scoped and budgeted.
Ready to build an AI solution that actually grows with your business? Ekipa specializes in turning ambitious AI concepts into scalable, production-ready reality through AI strategy consulting and hands-on implementation.



